引言
隨著互聯(lián)網信息的爆炸式增長,輿情分析系統(tǒng)成為政府、企業(yè)和社會組織監(jiān)測輿論態(tài)勢、預警潛在風險的關鍵工具。基于大數(shù)據(jù)的輿情分析系統(tǒng)架構中,數(shù)據(jù)處理與存儲服務作為核心組成部分,承擔著數(shù)據(jù)采集、清洗、整合與持久化存儲的重要職責。本文將從架構角度,深入探討數(shù)據(jù)處理及存儲服務的設計原則、技術選型及其在輿情分析系統(tǒng)中的作用。
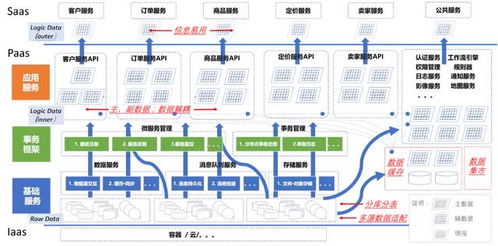
一、數(shù)據(jù)處理服務的設計與實現(xiàn)
數(shù)據(jù)處理服務是輿情分析系統(tǒng)的基石,負責從多源異構數(shù)據(jù)中提取有價值的信息。其架構通常包括以下關鍵環(huán)節(jié):
- 數(shù)據(jù)采集模塊:
- 通過爬蟲技術、API接口或日志收集工具,實時或批量抓取來自社交媒體、新聞網站、論壇等渠道的輿情數(shù)據(jù)。
- 支持多協(xié)議接入(如HTTP、Kafka、FTP),并具備去重和增量采集能力,確保數(shù)據(jù)的全面性和時效性。
- 數(shù)據(jù)清洗與預處理模塊:
- 對原始數(shù)據(jù)進行噪聲過濾、格式標準化、編碼轉換和實體識別(如人名、地名、機構名)。
- 利用自然語言處理(NLP)技術進行分詞、詞性標注和情感極性分析,為后續(xù)分析奠定基礎。
- 數(shù)據(jù)集成與轉換模塊:
- 將清洗后的數(shù)據(jù)轉換為統(tǒng)一的格式(如JSON、Avro),并整合至數(shù)據(jù)流水線。
- 采用流式處理框架(如Apache Flink、Spark Streaming)實現(xiàn)實時數(shù)據(jù)處理,確保低延遲響應。
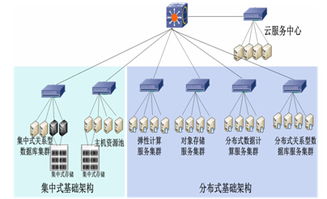
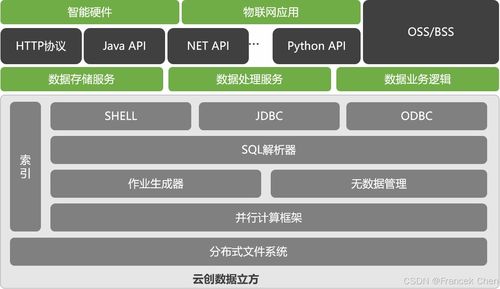
二、數(shù)據(jù)存儲服務的架構設計
數(shù)據(jù)存儲服務需滿足海量數(shù)據(jù)的高效存儲、快速查詢和可擴展性需求。其設計通常分為實時存儲與離線存儲兩層:
- 實時存儲層:
- 使用NoSQL數(shù)據(jù)庫(如Elasticsearch、HBase)存儲近實時輿情數(shù)據(jù),支持全文檢索和復雜查詢。
- 結合內存數(shù)據(jù)庫(如Redis)緩存熱點數(shù)據(jù),提升實時分析和儀表盤展示的性能。
- 離線存儲層:
- 基于分布式文件系統(tǒng)(如HDFS)或數(shù)據(jù)湖(如Delta Lake)存儲歷史數(shù)據(jù),用于深度分析和模型訓練。
- 采用列式存儲格式(如Parquet、ORC)優(yōu)化查詢效率,并利用數(shù)據(jù)分區(qū)和索引策略加速數(shù)據(jù)訪問。
三、關鍵技術選型與優(yōu)化策略
在數(shù)據(jù)處理與存儲服務中,技術選型直接影響系統(tǒng)的性能和可靠性:
- 數(shù)據(jù)處理框架:優(yōu)先選擇支持容錯和水平擴展的框架,如Apache Kafka用于數(shù)據(jù)流傳輸,Spark用于批量處理。
- 存儲引擎:根據(jù)數(shù)據(jù)訪問模式選擇合適的存儲方案,例如Elasticsearch適用于文本搜索,而Hive適合離線分析。
- 數(shù)據(jù)安全與合規(guī):通過加密傳輸(TLS/SSL)、訪問控制(RBAC)和數(shù)據(jù)脫敏技術,確保輿情數(shù)據(jù)的安全性和隱私保護。
四、實踐案例與挑戰(zhàn)應對
以某政府輿情監(jiān)控系統(tǒng)為例,其數(shù)據(jù)處理與存儲服務通過以下方式優(yōu)化:
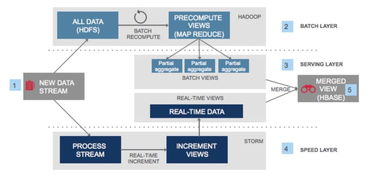
- 采用Lambda架構兼顧實時與批量處理,日均處理數(shù)據(jù)量達TB級別。
- 利用數(shù)據(jù)壓縮和冷熱數(shù)據(jù)分層存儲策略,降低存儲成本并提高查詢效率。
- 面臨的挑戰(zhàn)包括數(shù)據(jù)源的動態(tài)變化和存儲規(guī)模擴展,可通過微服務化和云原生技術(如Kubernetes)實現(xiàn)彈性伸縮。
結語
數(shù)據(jù)處理與存儲服務是輿情分析系統(tǒng)架構中的核心支撐,其設計需平衡性能、成本與可維護性。隨著人工智能和邊緣計算的發(fā)展,未來輿情系統(tǒng)將更注重實時智能處理與分布式存儲的深度融合,為輿情監(jiān)測提供更強大的技術保障。