隨著智能電網建設的不斷深化,電力系統正經歷著從自動化到智能化的深刻變革。在這一進程中,配電系統作為連接電網與用戶的關鍵環節,其運行狀態的精準分析與高效管理至關重要。全業務統一數據中心的提出,為整合分散的配電業務數據、挖掘數據價值提供了核心平臺。本文旨在探討基于該數據中心的配電分析應用中,數據處理及存儲服務的關鍵技術與實現路徑。
一、 數據處理服務的核心架構與流程
配電分析涉及海量、多源、異構的數據,包括SCADA實時數據、用電信息采集數據、設備臺賬數據、地理信息數據、氣象數據以及用戶行為數據等。數據處理服務作為連接原始數據與上層分析應用的橋梁,其核心任務在于實現數據的“提質”與“賦能”。
- 數據接入與集成:構建統一的數據總線或接入平臺,支持多種協議(如IEC 61850、104規約、MQTT等)和接口,實現配電終端、計量裝置、運維系統等各類數據源的實時、準實時及批量數據的可靠接入。通過數據清洗、格式標準化、冗余消除等手段,形成規范一致的原始數據池。
- 數據加工與治理:在原始數據基礎上,建立數據質量稽核規則,對數據的完整性、準確性、一致性和時效性進行監控與修復。通過關聯、融合、計算(如線損計算、負荷預測特征提取、設備狀態指標計算等),生成面向不同分析主題(如供電可靠性分析、線損精益化管理、配網故障研判、負荷預測與優化)的高價值衍生數據資產。建立統一的數據模型與資產目錄,實現數據的可發現、可理解與可信任。
- 數據服務化:將處理后的數據封裝成標準化的API服務或消息流,以松耦合的方式提供給上層的配電運行分析、規劃仿真、故障診斷、智能運維等應用。這包括實時數據推送服務、歷史數據查詢服務、專題分析數據服務等,支撐應用的敏捷開發與靈活調用。
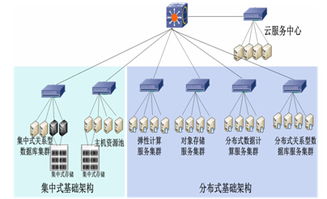
二、 存儲服務的分層設計與技術選型
面對配電數據體量大、類型雜、價值密度不一、訪問模式多樣的特點,存儲服務需采用分層、分域的混合架構,以實現成本、性能與擴展性的最佳平衡。
- 實時/時序數據存儲層:針對SCADA遙測、PMU等高頻采集的時序數據,采用專用的時序數據庫(如InfluxDB、TDengine或基于HBase的時序方案)。這類數據庫在數據壓縮、高速寫入、時間范圍查詢方面具有顯著優勢,能夠高效支撐實時監控、趨勢分析等場景。
- 海量歷史與明細數據存儲層:對于用電信息、事件記錄等海量明細數據,采用分布式大數據存儲框架,如Hadoop HDFS結合Hive/Spark,或云原生對象存儲服務。此層提供高可靠、低成本的海量數據存儲能力,支撐長期歷史數據回溯、批量離線分析與數據挖掘任務。
- 關系型與分析型數據存儲層:用于存儲經過加工治理后的高質量數據資產、模型參數、知識庫及業務元數據。可選用高性能關系型數據庫(如分布式MySQL集群、PostgreSQL)或MPP分析型數據庫(如ClickHouse、Greenplum),以滿足復雜關聯查詢、多維分析和報表生成的快速響應需求。
- 內存與緩存層:利用Redis、Memcached或內存計算框架(如Spark),緩存熱點數據、中間計算結果和實時分析狀態,極大提升高頻訪問和數據預處理的速度,為實時分析決策提供瞬時響應能力。
三、 數據處理與存儲的協同與挑戰
數據處理與存儲服務并非孤立存在,而是緊密協同。流處理框架(如Flink、Spark Streaming)可從實時存儲中消費數據,進行在線處理并寫回存儲或直接推送至應用;批量處理任務則定期從海量存儲中提取數據,加工后存入分析型存儲。面臨的挑戰包括:
- 數據安全與隱私保護:需建立貫穿數據全生命周期的安全防護體系,特別是用戶用電數據等敏感信息。
- 資源彈性與成本控制:云化部署與容器化技術有助于實現計算與存儲資源的彈性伸縮,優化總體擁有成本。
- 技術架構的持續演進:隨著邊緣計算、人工智能技術的融合,需考慮在邊緣側進行初步數據處理,并與中心形成云邊協同的架構。
結論:在全業務統一數據中心的支撐下,構建一個高效、可靠、可擴展的數據處理與存儲服務體系,是釋放配電數據潛能、驅動配電分析應用智能化升級的基石。通過分層存儲、流批一體處理、數據服務化等關鍵技術實踐,能夠有效應對數據洪流,為配電系統的安全、經濟、高效運行提供堅實的數據內核,最終推動配電網向主動自愈、互動優化、綠色高效的智慧配電網演進。